
The AI Gamble, Six Months On
The Mountain Is Only Half Climbed

In December I wrote The Architecture of a Gamble: Mapping the AI Value Chain. Given it’s been about 6 months, an update seems in order.
The architecture I outlined had 4 layers: compute supply chain, operational infrastructure, intelligence and application. Each layer has to justify its own expenses, which contribute to the revenues of the lower layers. When those aren’t justified, the whole structure is a gamble on the outcomes of the upper layers. That said, the immediate term for lower layers can be remarkably sound, because they get paid now, not later.
This story is only half written, so we can look at how each layer is doing today. Even when that story looks good, we shouldn’t extrapolate to the future. Each increment of demand must prove itself, both in terms of feasibility and in terms of timing.
How is each layer doing today?
Layer 1: The Compute Supply Chain
The main influence on this layer is the inputs from Layer 2. Since those plans have kept progressing as planned a year ago, it should be unsurprising that this layer has done well. Revenues continue to increase and stability looks favorable. The main change here is that competition is growing. The availability of chips designed in house, TPUs, Trainium and more, have grown. The efforts to make Intel capable of competing with TSMC have continued. TSMC has continued expansions of its own.
Additionally, memory and CPUs have been pulled closer to the middle. Memory was already a bottleneck and has become more central. GPUs have remained central, but share much of the spotlight with memory now. CPUs have moved from trivialities, to moderate importance.
Layer 2: The Operational Infrastructure
The situation at this layer has firmed up significantly in the past 6 months. Revenue for delivered compute has continued to grow. Additionally, commitments have been disclosed, adding stability. Disclosures about commitment numbers don’t express the exact terms, so we don’t know if these could reverse.
More importantly, everything is broader here. OpenAI and Anthropic are using compute from all platforms. xAI showed how to recover from a failure, at least partially, by selling unused compute to Anthropic.
All that good news shouldn’t ignore that there’s still significant spending planned that will have to justify itself. The revenues of today (+$100 billion ARR) are roughly proving that last year’s $410 billion in spending isn’t going to be unproductive. That doesn’t tell us enough about this year’s $700 billion, nor next year’s $1 trillion. So long as those keep growing quickly, the risk that expected revenue to cover it never appears should remain a live discussion.
Layer 3: The Intelligence
There are many positive updates here. The best ones concern Anthropic, which is a moderately bad story for OpenAI. Revenues have grown considerably. Anthropic expects to be profitable. Enterprise revenues have grown considerably. Could this reverse? Maybe. Much usage is still prototypes, experimental, or otherwise dependent on expectations. But it seems unlikely. As I covered last week, there’s more pulling us forward than back here.
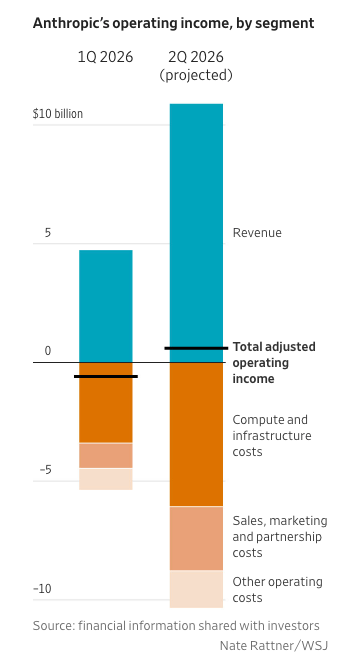
Layer 4: The Application
This layer still contains a large amount of uncertainty. The most significant use case, software development, is fundamentally another layer. Last week I covered dynamics of token usage by the application layer. While this is one of the longest articles I’ve written, it only covers dynamics, not actual numbers, and only a few of the most important.
To be truly solid, the various parts of the application layer need recognition that value is being created. That’s hard, because there’s a lot that would need to be measured here, and many of the things you want to measure, are both difficult and emerge with lagging indicators.
Adversarial usage, in marketing ($660 million), legal ($650 million), and sales ($390 million), is following behind coding and IT usage.
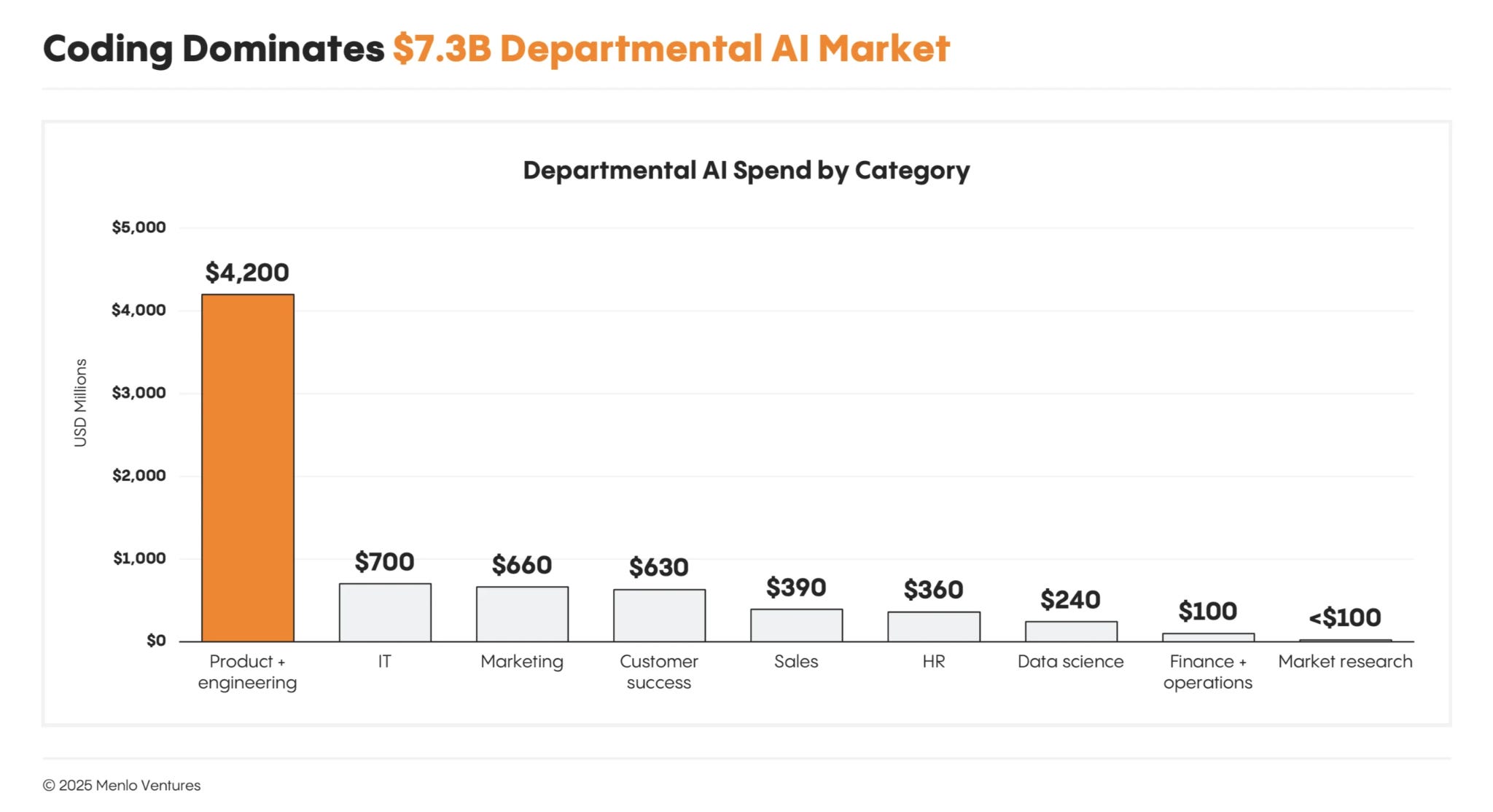
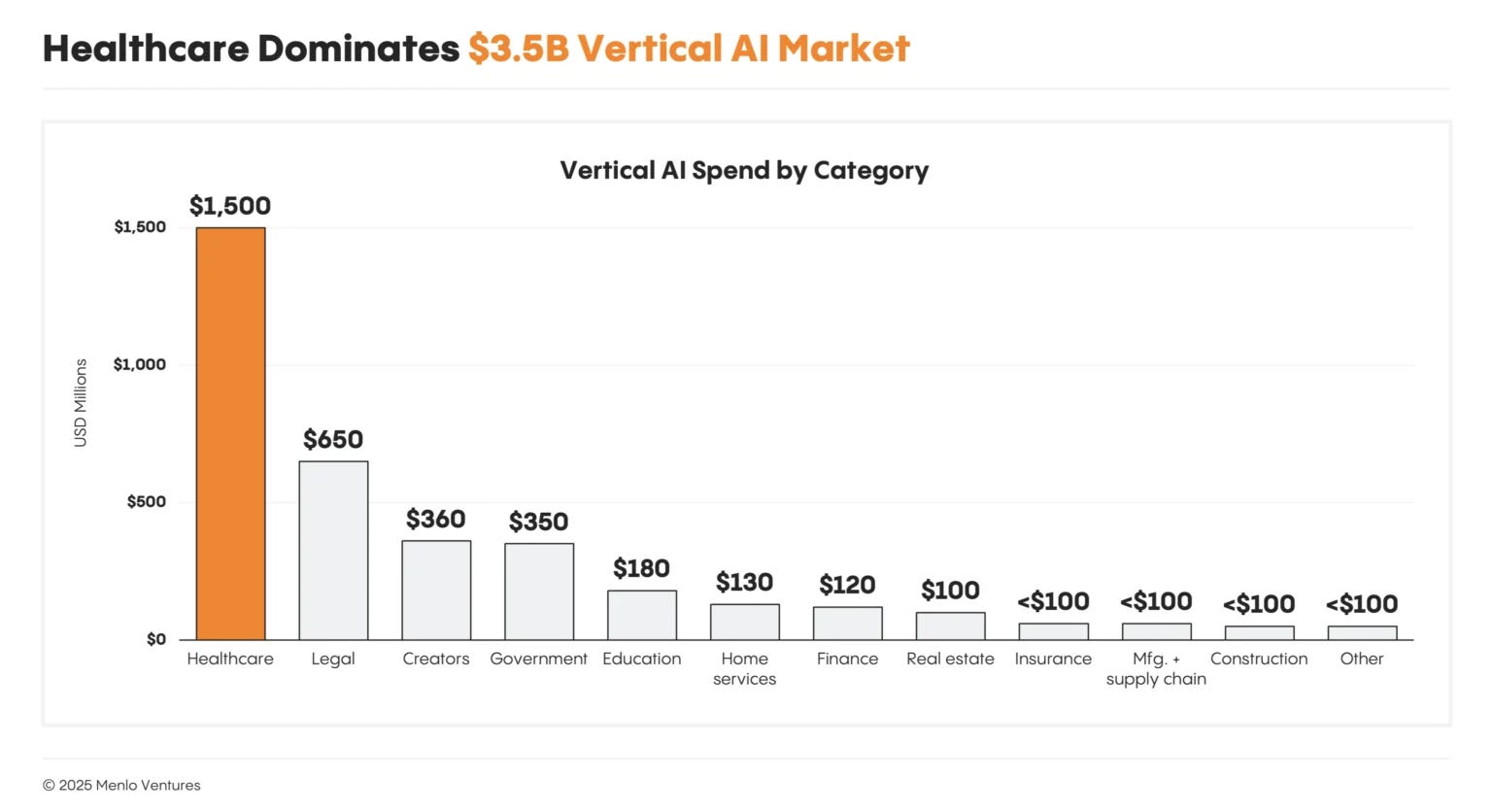
Early adoption from sales and advertising, shapes how much effects need to be proven. From a financiers perspective, this isn’t a problem, maybe even positive. From someone worried about employment demand, it also isn’t a problem.
But from a social perspective, it’s not sound. We can’t expect significant positive value to come out of adversarial sectors. We want to see demonstrated productive revenue, and we want to see cases where freed labor is reutilized in growth sectors.
Conclusion
Is the AI industry past the “bubble” discussion? No. Certainly not in terms of stock prices and valuations. In terms of CapEx spend, and the likeliness of future contractions or firm failures, it’s on firmer footing, but the story still progresses as the mountain is only half climbed. You might say that anyone who put 2026 as a specific timeline for their concerns, has missed the mark, and there are many who did. But overconfident predictors don’t make an effective counter-argument to more general views.
Postscript: Fable 5
It would be unusual not to update here, as I’ve written about security in the past. It took a little while to become comfortable that I had enough facts as the administration’s story came out with so few details. It was hard for me to judge right off if that was because they had good information they didn’t want to share, or were just behaving irrationally. But the naive assumption seems to be true, they were behaving irrationally.
“Asking” for a shutdown, using bad evidence that doesn’t demonstrate any real harm is bad for everyone. For safety-minded people, it’s effectively “calling wolf”, and undermines any future action based on good evidence. For the safety-optimistic, aka accelerationist, it’s bad for the obvious reasons, but also bad because it creates a precedent of using bad evidence. This creates more uncertainty.
All parties, at least rationally, should want actions that are based on good evidence only. They might disagree on where the evidentiary bar should be, but it’s clearly bad when it’s randomly chosen. Since the capabilities they have evidence of being able to reproduce with a limited jailbreak are universal amongst models, you would have to ban them all. But they aren’t all banned, just one. That’s not a consistent system, and it should be obvious why that’s generally illogical as an outcome.
Related articles

The Architecture of a Gamble

A while back I talked about producing an analysis of the AI industry. I’ve put together something pretty extensive, but on reflection, I’ve decided to put it out in multiple parts. This post today functions more as an outline, where the following posts will dive more into each layer of this stack and then finally look in more depth at the macro-economic aspects.
AI and the Zero-Sum Game

AI is advancing quickly, and if there’s any one consensus about it, it is that it will have broad impacts on jobs. What impact, is an area of more debate, but it’s uncommon to view it as non-impactful. Some believe that jobs will disappear, and there would be large amounts of unemployment. Some draw on past periods of technological change, such as the Industrial Revolution or the advent of the internet, and believe that advances ultimately lead to new jobs that didn’t previously exist.