
AI Safety Is Underfunded by Design
A Model for Incentive-Aligned AI Safety Policy

Dean Ball recently put his finger on something important about AI liability and incentives:
In general, market actors do not have great incentives to protect against catastrophic risks. They are massive negative externalities, often dwarfing the balance sheet of any individual firm. Say Anthropic releases a model that a malicious actor uses to conduct a cyberattack that does $5 trillion dollars in damage. Anthropic is only worth $800 billion, so if they get sued for $5 trillion, they are already well past the point of insolvency. A catastrophic harm may well already be “lights out” for Anthropic, or any other company, so there is little incentive to avoid them, if doing so entails real costs in the present day.
He’s right about the structure of the problem — but “little incentive” understates the precision available here. AI companies do have incentive to avoid catastrophic outcomes, just systematically less than society needs them to. That gap can be quantified, and quantifying it points toward what a corrective policy should actually look like.
The concerns he’s talking about — catastrophic risks — share a structural feature that distinguishes them from others: they are lumpy. A single catastrophic event, rather than a diffuse trend. The incentive is quite large, but not as large as it should be. These dynamics are worth exploring, as those ultimately shape if and how we structure a response.
Consider a hypothetical AI company, worth $800 billion. Now consider a hypothetical event causing $5 trillion in damages. If this event happened, that AI company would be out of business, so they have an incentive to prevent it. But how much incentive? The most they can lose is the whole company, so $800 billion. Since a lot of that is goodwill, in reality, losses become irrelevant earlier. For the sake of example, we’ll say $400 billion. If you had to pay half your market cap, you’re not worth $400 billion, you’re bankrupt, and worth $0. All claims greater than $400 billion have equal impact, since each produces the same outcome, a total loss.
This creates an imbalance between societal goals and the AI company’s goals. That imbalance could lead to underinvestment in safety, or risk taking that is out of alignment with societal goals.
We can quantify this imbalance, by modeling a damage cap in expected value calculations. If our $5 trillion event has a 1 in 10,000 chance of occurring, the uncapped expected value of avoidance is $500 million. With a damage cap of $400 billion, it’s only $40 million. Society should want that other $460 million in incentive to be shared by the AI company, but without an arrangement, it’s not.
Refinements
I used a simple model above, with linear effectiveness of investment in safety. It isn’t linear. In a linear model, spending $500 million reduces risk to zero, and $40 million reduces it to 1/12th of that, or one 1 in 9,166. But we could imagine, in fact we should expect, that the first $40 million does more than the next $40 million. Maybe the first reduces the risk to 1 in 100,000, and the next to 1 in million. It’s the same proportional improvement — 10x. But in the first case it reduces the risk from 100/million to 10/million for a total reduction of 90/million. The second case reduces from 10/million to 1/million, for a total of 9/million reduction.
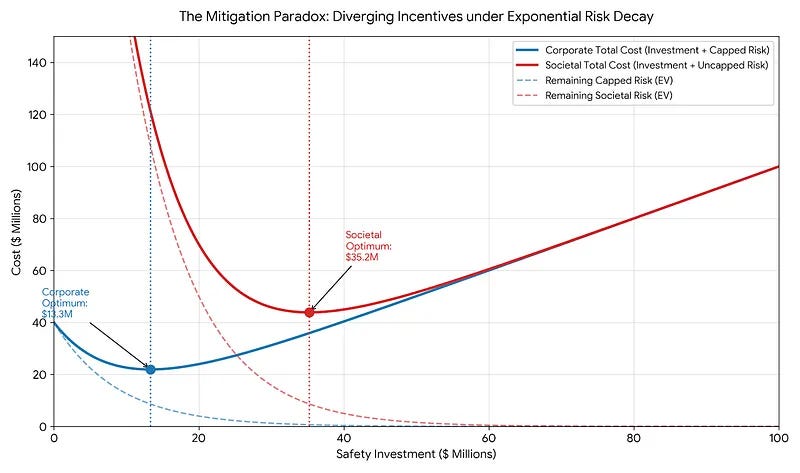
To illustrate, I constructed a model that used logarithmic decay from the initial 1 in 10,000. In this model, under their default incentives, the AI company would want to spend $13.3 million to reduce their expected risk from $40 million to $8.7 million. But the societal risk is still $122 million at this point.
The goal of a corrective policy would be for the AI company to act upon the societal risk, which justifies spending $35.2 million to reduce the societal risk to $8.7 million.
Further refinement considers whether organic spending is more efficient than regulatory-induced spending. For example, if regulatory-induced spending had half the effect per dollar as organic spending, not only would the spending go up, but the residual damage would be higher.
In Scenario 1, all spending is equally valuable. In Scenario 2, the company spends efficiently up to its capped motivation, after which each real dollar buys only $0.50 of effective safety. And finally in Scenario 3, all spending is at 50% effectiveness.
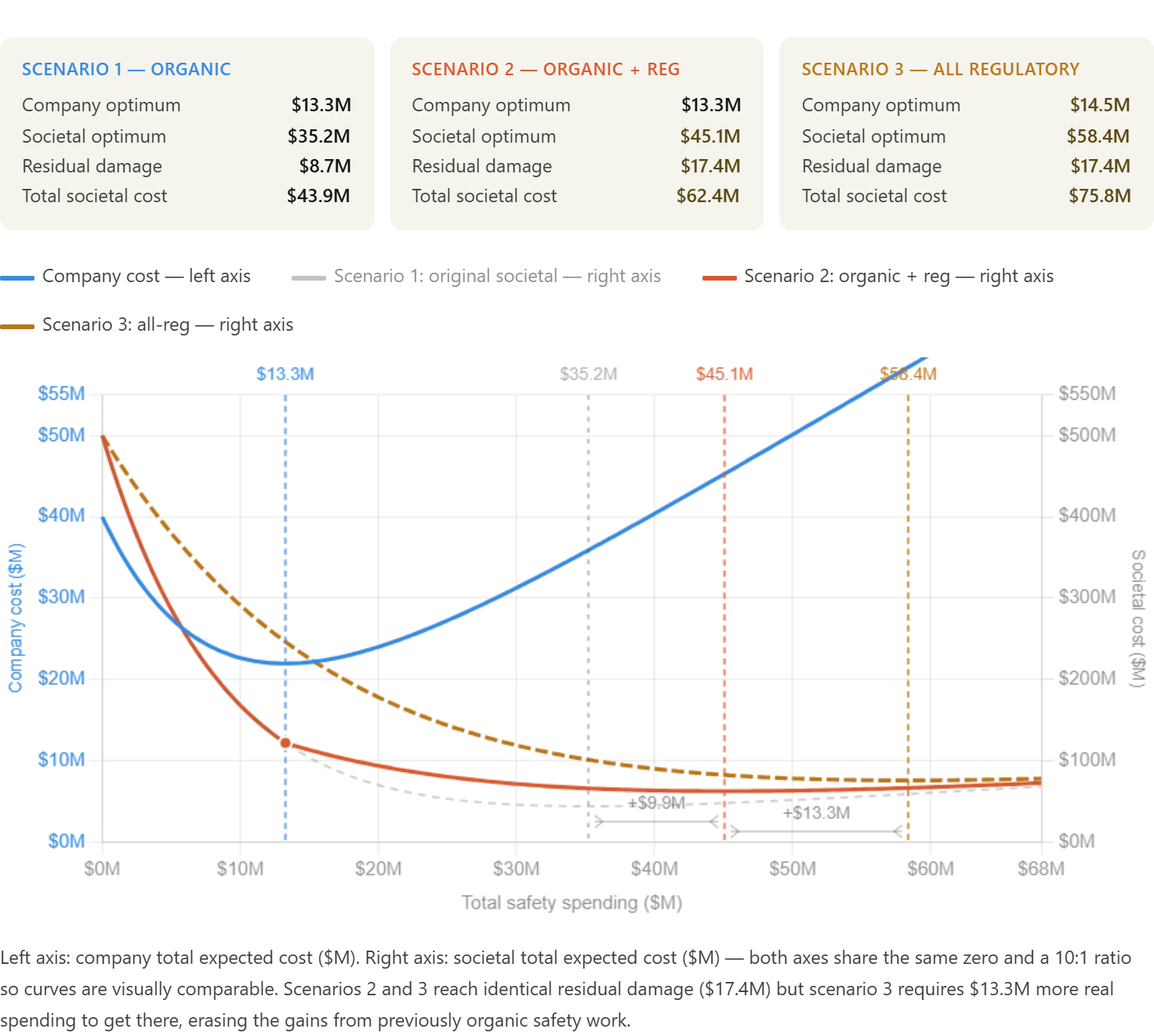
You can explore other scenarios in the linked single page app (GitHub Repo). You can experiment with different decay functions, damage sizes and company sizes.
Organic Forces
We’d also be doing ourselves a disservice if we didn’t recognize the outstanding work that AI companies have done — Anthropic most of all. Commercial incentives alone aren’t sufficient. The stories about the founding of DeepMind and OpenAI make clear that good intent has played a positive role. But in a commercial world, you can’t depend on good intent to reliably show up or win internal contests. The pressure to go off track is substantial. For something this important, that’s a lot of trust. We want to use these forces, because they are efficient, but must not be naive either.
We don’t want to take organic forces for granted. If we assume they don’t need support, they might disappear. If we don’t acknowledge their value, we might strangle them.
Small Firms
The alignment problem becomes more acute for smaller companies. What if a smaller startup, with none of the weight of a larger company — little to lose, and everything to gain — rushes ahead, and skips best practices that avoid harm?
The leading labs are large (Anthropic, OpenAI and Google), but we shouldn’t take that for granted. Frontier model training costs keep going up, but the costs for a particular level of capability keep going down. DeepSeek proved that moats are much shallower than assumed.
You do want to avoid locking out startups, but also need a baseline that ensures safety isn’t skipped. A first step here is ensuring safety practices are shared. That lowers their costs in pursuing safety.
The current voluntary norm — leading labs sharing safety methodology despite having competitive reasons not to — is a favorable state of affairs that formal structure can preserve and extend. It will take organization to make it work at a deeper level. Sharing details of some safety practices publicly can add risk, so a well-trusted network for sharing enables more than just the public domain approach. Formalizing sharing as a condition of operating at the frontier, both preserves what already occurs, and can extend it more deeply.
Regulatory Shape
The model makes the policy objective concrete: close the gap between what the company is motivated to spend and the societal expected value, without crowding out the organic safety investment that’s already happening.
A naive response assumes insurance is enough, and the challenge is finding a large enough reinsurer to pay out. An even more naive response assumes this challenge can be fixed by inserting the federal government as a backstop to the insurance. The flaw in this thinking is that it makes society responsible for paying itself back for harm done to it. This won’t work. The harm would have been done. Society would pay for the majority of the consequences of the gamble the AI companies made.
These dynamics suggest that effective regulation needs balance, in order to use organic forces, and yet also not leave a gap. Dean is right that it improves the case for government involvement. If there’s a gap between the company’s incentives and the societal incentives on a topic so important, we should align those.
An industry body that both shares security practices and sets standards is a start. Shared excess liability amongst all AI companies would add to existing incentives. If one fails to prevent harm in a small way, that company fails alone. If one fails in a big way, they all fail. Expanding the pool in this way is better than involving the government, as these are the players with the ability to influence the risk. Those incentives will encourage maintaining quality standards, but keep the standards moored to efficiency and effectiveness.
That’s still not enough though, so a government body above that respects the value of organic forces, would be a second step. The challenge here is how to prevent this body from losing interest in efficiency. It’s natural for them to be interested in effectiveness, but efficiency comes with more difficulty. If standards ignore efficiency, you undermine the organic forces and risk taking a step backwards instead of forwards.
What doesn’t work?
The framework I’m discussing, can appear to be a compromise between two points of view. That’s not the intent. There is no intent to choose a middle point, in order to satisfy two points of view. I think the merits of this model fit without any politics.
The model does however balance multiple forces, and is not aligned with any maximal plan. That type of balance only makes sense if the maximal plans aren’t reasonable. To make it clear, I don’t support any maximal plans. It will take additional posts to flesh out why, and others have defended these points independently. But in the light of outlining my thinking, the basic is:
AI bans: You have no chance. You have no global solution. It’s not a good idea in the first place, as AI will be very useful, but that’s not the biggest flaw. The biggest flaw is all of the partial wins - company X refuses to use AI, country Y bans AI - they all fail in the end and don’t contribute to any goal aligned with the best case for a ban.
No regulations: Clearly something is needed here. This group is somewhat of a strawman though, as even people like Dean Ball see a role for regulation. The better critique is that there are many people who are implicitly “no regulationists”, because they oppose everything proposed and don’t put together enough to actually do something.
Top-down regulations: Strangling organic safety efforts in top-down paperwork is a surefire way to fail. That doesn’t mean there isn’t a top, but it does mean, it can’t be total, and since it’s starting later, it should expect to start small and iteratively find its fit.
Clearly, there are more details to cover here. I’ve only touched on one dynamic that sets an overall tone, but you’d eventually need a list of initial best practices, and an expert-led group to maintain them. You’ll need a mechanism to choose that group, and a list of powers and limitations that define how they work together, and resolve conflicts. I’ll leave those questions for a future post though.